
What is imbalanced data?
Imbalanced data refers to those forms of datasets where the target class has an uneven distribution of observations, i.e., one class label features a very high number of observations and therefore the other incorporates a very low number of observations.
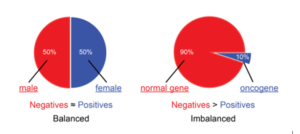
Let’s see it with an example-
Consider a dataset of 1000 patients, of which 80 have cancer and the remaining 920 are in good condition. Because the dominant class is nearly nine times larger than the minority class, this dataset is an example of an unbalanced dataset. In this instance, “Cancer” is in the minority while “Healthy” is the dominant class.
Therefore, a dataset that has an imbalance is one in which the majority class is significantly bigger than the minority class. The size of the majority class has no upper bound. It is still an unbalanced dataset even though the majority class is twice as big as the minority class.
Techniques for handling imbalanced datasets-
- Use the right evaluation metrics-
Using the wrong rating scales for models built with unbalanced data can be harmful. Imagine that the image above represents our training data. A model that labels all testing samples as “0” will have an outstanding accuracy (99.8%) if accuracy is used to gauge a model’s usefulness, but obviously this model won’t offer us any useful information.
- Resample the training set-
2.1 Under-sampling-
By minimising the size of the abundant class, under-sampling evens out the dataset. When there is an enough amount of data, this strategy is applied. A balanced new dataset can be produced for further modelling by keeping all samples in the uncommon class and randomly choosing an equal number of samples in the plentiful class.
2.2 Over-sampling-
Oversampling is used when there is not enough data. Try to balance the data set by increasing the size of the outliers. Instead of excluding common samples, new rare samples are generated using techniques such as replication, bootstrap, or SMOTE (Synthetic Minority Hyper Sampling Technique).
- Use K-fold Cross-Validation in the Right Way-
Remember that oversampling creates new random data based on the distribution function using smoothing to generate new random data from a sample of the observed anomalies. If we use cross-validation after oversampling, we are essentially oversampling our model to get a specific misleading result. Therefore, cross-validation should always be done before data oversampling, just as feature selection should be done. Randomization can only be added to the data set by repeatedly regrouping the data to ensure that there are no allocation problems.
- Ensemble Different Resampled Datasets-
Adding extra data is the simplest technique to successfully generalise a model. The problem is that predefined classifiers such as logistic regression and random forest often generalize by omitting unusual classes. Building n models using all data from rare classes and different samples from rich classes is a simple good practice. For example, if you want to merge 10 models, you can keep 1.000 instances of uncommon classes while randomly selecting 10,000 instances of rich classes. Simply divide 10,000 examples into 10 equal parts and train 10 different models.
- Resample with Different Ratios-
By experimenting with the ratio of rare and abundant classes, prior strategies can be improved. The data and models used have a significant impact on the ideal relationship. However, it is worth experimenting with alternating group training ratios rather than training each model at the same ratio. If ten patterns are trained, one pattern with a rare/abundant ratio of 1:1 and another with a ratio of 1:3 or even 2:1 makes sense. The weights assigned to the categories may vary depending on the model used.

