
Introduction
In the rapidly evolving landscape of artificial intelligence (AI), DeepSeek has emerged as a formidable force, pioneering advancements in machine learning, reasoning capabilities, and code generation. Founded in 2023, DeepSeek is dedicated to developing Artificial General Intelligence (AGI), pushing the boundaries of AI to solve complex reasoning and coding tasks efficiently.
DeepSeek’s approach incorporates state-of-the-art methodologies such as reinforcement learning (RL) and a multi-stage training process that ensures exceptional performance. One of its flagship models, DeepSeek-R1, has set new standards in logical reasoning, mathematical problem-solving, and coding proficiency. Additionally, DeepSeek’s Mixture-of-Experts (MoE) architecture in DeepSeek-V3 has significantly enhanced scalability and computational efficiency.
This blog delves into the workings of DeepSeek, exploring its training methodologies, models, and impact on the AI landscape.
Understanding DeepSeek and Its Key Models
DeepSeek has introduced multiple models tailored to different AI applications. Below are some of the key models that have been developed:
1. DeepSeek-R1: The AI Reasoning Powerhouse
DeepSeek-R1 is an advanced large language model (LLM) designed to excel in reasoning tasks. Unlike traditional models that rely heavily on supervised fine-tuning (SFT), DeepSeek-R1 incorporates reinforcement learning from the very beginning. This unique approach enables the model to develop its own logical reasoning structures without being overly dependent on manually labeled datasets.
Key Features of DeepSeek-R1:
- Cold-Start Data Incorporation: Unlike models trained purely on RL, DeepSeek-R1 first undergoes training with high-quality curated datasets to establish a strong foundation.
- Self-Developed Chain-of-Thought (CoT) Reasoning: The model learns how to break down complex problems into sequential steps, mirroring human cognitive abilities.
- Multi-Stage Training Process: The combination of RL, rejection sampling, and supervised fine-tuning ensures high accuracy and readability.
- Performance Benchmarking: DeepSeek-R1 achieves performance levels comparable to OpenAI-o1 across math, code, and logical reasoning tasks.
2. DeepSeek-R1-Zero: A Pure Reinforcement Learning Model
DeepSeek-R1-Zero is an experimental version of DeepSeek-R1 trained exclusively with RL and no supervised fine-tuning. While this approach significantly enhances its self-learning ability, it comes with challenges such as repetitive reasoning steps and potential readability issues. However, this research paves the way for AI models to train themselves without human intervention.
3. DeepSeek Coder: A Specialized Code Generation Model
DeepSeek Coder is a language model optimized for programming tasks, trained on a dataset comprising 87% code and 13% natural language documentation in English and Chinese. With a pre-training dataset exceeding 2 trillion tokens, this model is built to assist developers in coding, debugging, and automating software engineering tasks.
DeepSeek Coder Key Highlights:
- Repository-Level Code Corpus: The training data includes entire repositories rather than isolated code snippets, ensuring contextual understanding.
- 16K Context Window:Allows the model to retain long-range dependencies in code, enhancing its ability to generate meaningful solutions.
- Fill-in-the-Blank Task: A unique pre-training task that helps the model improve its contextual reasoning capabilities.
4. DeepSeek-V3: Mixture-of-Experts (MoE) Scaling
DeepSeek-V3 is a powerful MoE language model boasting a total of 671 billion parameters, with 37 billion activated per token. This architecture optimizes computational efficiency by activating only the necessary experts for each task, reducing the burden on hardware while maintaining high performance.
Key Innovations in DeepSeek-V3:
- Multi-Head Latent Attention (MLA): Improves model efficiency and token processing speed.
- Auxiliary-Loss-Free Strategy: Enhances load balancing without requiring additional loss functions.
- Multi-Token Prediction Training: Strengthens the model’s ability to handle complex sequences effectively.
The Training Methodology Behind DeepSeek Models
DeepSeek employs an innovative, multi-stage training approach that significantly enhances its models’ performance. Below, we explore the various training methodologies used in DeepSeek models.
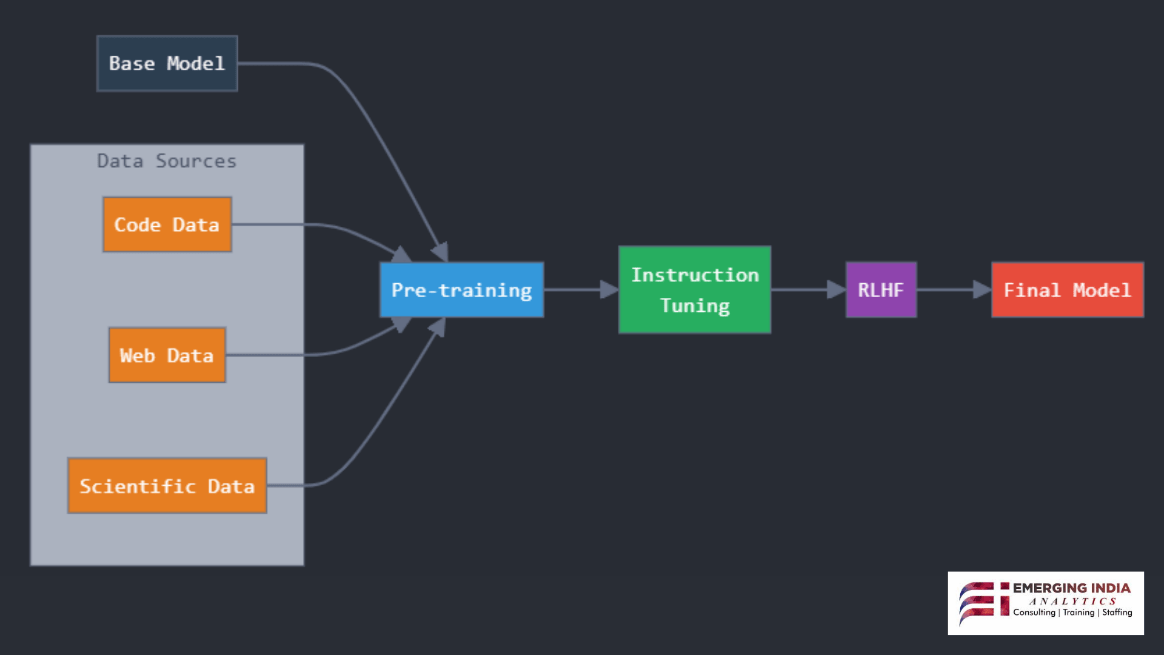
-
Reinforcement Learning-Driven Training
Unlike traditional models that primarily rely on supervised learning with labeled datasets, DeepSeek-R1-Zero and DeepSeek-R1 leverage reinforcement learning. This enables the models to:
- Learn from trial and error without predefined answers.
- Develop complex reasoning abilities independently.
- Improve problem-solving accuracy through self-generated feedback loops.
-
Multi-Stage Fine-Tuning Process
DeepSeek enhances its models using a stepwise fine-tuning process:
Stage 1: Cold-Start Data Pre-Training
- This step involves training on high-quality, human-curated datasets to establish a fundamental knowledge base.
Stage 2: Reinforcement Learning with Rejection Sampling
- The model generates multiple responses and selects the most accurate or logical response based on reward feedback.
Stage 3: Supervised Fine-Tuning
- Human annotations refine the model’s output, improving readability and reducing repetition.
Stage 4: Final RL Optimization for Generalization
- The last stage further refines the model, ensuring it generalizes well across diverse tasks.
- The Role of MoE in DeepSeek-V3
DeepSeek-V3’s Mixture-of-Experts (MoE) framework allows selective activation of model parameters, making large-scale models more efficient. This approach improves inference speed while reducing computational costs.
Applications and Impact of DeepSeek Models
DeepSeek’s models have numerous applications across different domains. Below are some of the key areas where DeepSeek is making a significant impact:

- AI-Powered Coding Assistants
DeepSeek Coder serves as an intelligent programming assistant, helping developers with:
- Code generation and debugging
- Automated software documentation
- Context-aware code completion
- Mathematical and Logical Problem Solving
DeepSeek-R1 has demonstrated superior reasoning skills in:
- Complex mathematical computations
- Logical inference problems
- Chain-of-thought reasoning in natural language processing (NLP)
- Research and Scientific Discovery
DeepSeek’s models are increasingly being used for:
- Hypothesis generation in scientific research
- Automating data analysis in experimental studies
- Assisting in large-scale knowledge synthesis
- Future Prospects: Towards Artificial General Intelligence (AGI)
DeepSeek’s ultimate goal is to achieve AGI, where AI can perform human-like reasoning across multiple domains. By continuously refining its reinforcement learning strategies, DeepSeek aims to bridge the gap between specialized AI models and truly generalizable AI systems.
DeepSeek AI And Its Influence On The American Stock Market Crash

How DeepSeek AI Shook the Financial Markets
In late January 2025, the American stock market witnessed significant turmoil following the release of DeepSeek’s advanced AI model, R1. DeepSeek, a Chinese AI company, introduced R1, an AI system that demonstrated capabilities comparable to leading U.S. models but at a fraction of the development cost. This unexpected technological leap sent shockwaves through the global financial sector, as investors scrambled to reassess the competitive balance between China and the United States in artificial intelligence.
The Market Fallout
The unveiling of DeepSeek R1 led to a sharp decline in major U.S. technology stocks, particularly those deeply invested in AI. Nvidia, a leading chipmaker for AI applications, suffered the most significant hit, with its market capitalization plummeting by approximately $600 billion in a single day—one of the largest losses in market history. The shockwave extended across the broader tech market, causing the S&P 500 to drop by 1.5% and the Nasdaq to fall by over 3%. These declines reflected investor fears that DeepSeek’s cost-effective AI technology could disrupt U.S. dominance in the sector, potentially diminishing revenue prospects for American AI giants.
Geopolitical and Economic Implications
Beyond the immediate financial fallout, DeepSeek’s breakthrough has intensified geopolitical tensions between the U.S. and China. Reports indicate that the U.S. government is considering further restrictions on AI chip sales to Chinese firms, aiming to curb China’s advancements in AI technology. This regulatory uncertainty has added to investor concerns, contributing to heightened market volatility.
The Future of AI and Financial Markets
DeepSeek’s impact on the stock market highlights the growing influence of AI innovations on global economies. As AI models become more powerful and accessible, financial markets must adapt to rapid technological shifts. While DeepSeek’s R1 has demonstrated the disruptive potential of AI, it also raises questions about the long-term stability of AI-driven industries and the need for regulatory oversight to mitigate market shocks. The unfolding developments will be crucial in shaping the future of AI’s role in global financial systems.
Comparison of DeepSeek AI with Other Leading AI Models
| Feature | DeepSeek R1 | GPT-4 | Gemini | Claude 2 | LLaMA 2 | Falcon |
| Reasoning Ability | Advanced multi-step reasoning | Strong, but less optimized for reasoning | Good, but less refined for logic tasks | Strong, but a slower inference | Open-source, but less refined | Competitive, but lacks scalability |
| Training Efficiency | Cost-effective, optimized training | High cost due to compute demand | High compute and energy-intensive | Requires large-scale hardware | Open-source, but costly for fine-tuning | High cost for scaling |
| Computational Cost | Lower hardware dependency | Requires extensive GPU clusters | Expensive cloud-based processing | Higher latency due to complexity | More accessible, but requires tuning | Expensive scaling process |
| Multilingual Capability | Superior, trained on diverse global data | Good, but some languages underperform | Strong multilingual support | Decent, but limited in some languages | Primarily English-focused | Moderate multilingual ability |
| Stock Market Impact | Direct influence on financial markets | Used in financial models but indirect | Limited impact on global finance | Less usage in financial forecasting | Rarely applied to market predictions | Emerging, but not dominant |
| Real-time Adaptability | Rapid updates and adaptability | Updates require significant retraining | Periodic updates, not real-time | Slower adaptability | More flexible but not real-time | Requires heavy modifications |

